

K5 la risposta al Pentium
(a cura del Dott. Greg)
Realizzato da Roberto Buricchi e Leonardo Grassi
![]()
K5 la risposta al Pentium
(a cura del Dott. Greg)
Realizzato
da Roberto Buricchi e Leonardo Grassi
![]()


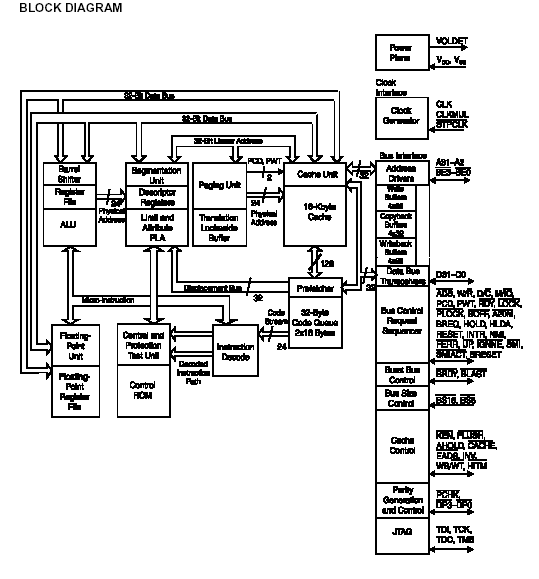
Il processore Amd K5 utilizzava un'architettura superscalare di tipo Risc, era costruito con tecnologia Cmos a 0.35 micron conteneva 4.3 milioni di transistor. Il suo nucleo superscalare di tipo Risc consisteva in 6 unità di esecuzione: 2 unità logiche aritmetiche (ALU), 2 unità load/restore, una unità Branch ed una unità di floating point (FPU).Il nucleo superscalare del K5 era pienamente indipendente dal bus x86 tramite la conversione delle istruzioni x86 a lunghezza variabile in semplici operazioni Risc a lunghezza fissa dette ROPs (risc operations) che sono più facili da maneggiare e più veloci da eseguire. Una volta che l'istruzione x86 è stata convertita un dispatcher (spedizioniere) invia 4 ROPs ,alla volta, al nucleo superscalare. Il nucleo della cpu può eseguire un picco massimo di 6 ROPs per ciclo di clock. Le particolarità del core del K5 sono il supporto per il data forwarding (invio dei dati) e il data bypassing per inviare immediatamente il risultato di una esecuzione alle istruzioni successive. Questo elimina il ritardo di scrittura e di lettura dei risultati all'interno dei registri estesi e alla memoria estesa.
Esecuzione fuori sequenza
Il K5 implementa l'esecuzione fuori sequenza per eliminare i ritardi dovuti alle pipeline. Ogni unità di esecuzione ha due stazioni di prenotazione (Reservation stations) che contengono già le ROPs prima che queste vengano eseguite (tranne l'Fpu che ne ha una sola). I ROPs possono essere pubblicati fuori sequenza dalle stazioni di prenotazione, ma possono anche essere eseguiti fuori sequenza. Alcune unità d’esecuzione, infatti, svuoteranno le loro stazioni di prenotazione prima di altre. Dal momento che ogni unità d’esecuzione può operare indipendentemente, le altre unità possono continuare l'esecuzione anche quando una più unità invece si fermano. Un Buffer a 16 ingressi (16-entry Reorder Buffer) tiene traccia della sequenza originale dell'istruzione e si accerta che i risultati siano posti nel corretto ordine.
Registri
L'architettura ha solo 8 registri per tutti gli utilizzi. Ciò aumenta significativamente la riutilizzazione del registro (load and store) e le dipendenze del registro creando quindi un collo di bottiglia nell'esecuzione dei dati. La riutilizzazione del registro è indirizzata con le unità d'esecuzione multiple (load/store) e con una cache a doppio accesso. Il processore K5 usa la rinominazione del registro per superare le dipendenze del registro; registri logici multipli per ogni registro fisico permettono alle unità di esecuzione di usare simultaneamente lo stesso nome del registro fisico.
Bus d’Interfaccia a 64bit
Il K5 usa un bus dei dati a 64 bit che fornisce un alto rendimento e supporto per i percorsi dei dati a 64 bit. Come il codice e i dati entrano nell'unità dell'interfaccia del bus, la cache interna si riempie continuamente alla velocità di 5 cicli di clock. L'incremento della larghezza di banda del bus dati del K5 e il continuo processo di riempimento della cache riduce i ritardi d’elaborazione portando ad un incremento delle prestazioni.
Istruzioni precodificate x86
Mentre i processori di 4° generazione elaborano 1 istruzione x86 a lunghezza variabile e le cpu di 5° generazione due istruzioni. Il K5 secondo Amd impiega tecnologie innovative per elaborare più di 4 istruzioni x86 per ogni ciclo di clock. Ogni byte del codice che entra nella cpu è etichettata con l'informazione allegata al predecode (predecodifica) che identifica i contorni dell'istruzione x86 (che vanno da 8 a 120 bit) permettendo così di allineare istruzioni x86 multiple. Una volta allineate, le istruzioni sono assegnate alle posizioni di emissione per una migliore esecuzione dell'istruzione contribuendo quindi ad un aumento delle performance. Oltre ad individuare dove inizia e finisce l'istruzione x86, l'informazione del predecode identifica la posizione del opcode e il numero delle operazioni semplici di tipo Risc (ROPs) che l'istruzione singola x86 richiede per la traduzione successiva. Dopo che le istruzioni x86 vengono predecodificate sono caricate nella cache riservata alla memorizzazione delle istruzioni. Quando accedono alla cache d’istruzione le istruzioni speculative sono spinte nella coda del Byte e attendono la successiva decodifica. La coda di Byte non solo contiene le istruzioni x86 ma anche il predecode, le etichette o tags associate al predecode che contrassegnano la posizione e il tipo d’operazione d’ogni istruzione.
Il decoder del K5 converte le istruzioni complesse x86 nelle relativamente semplici operazioni di tipo Risc ad esecuzione veloce che hanno una lunghezza fissa e sono facili da elaborare. Simultaneamente, gli operandi devono eseguire le ROPs che sono prese dall’archivio del registro o dal buffer del registro. All'inizio del processo di decodifica, il decoder fa lo scanner delle istruzioni x86 e alloca le istruzioni alla posizione di decode (decodifica) appropriata. Quest’allocazione dipende dal tag (etichetta) a 5bit assegnata ad ogni istruzione x86 durante la predecodifica. Quando l'istruzione predecodificata passa attraverso il decoder del K5, il numero di operazioni Risc che deve essere uguale all'istruzione x86 è già conosciuto dal predecoding. Tutto questo porta ad un risparmio di tempo e quindi a prestazioni superiori. Durante l'allocazione le vie dell'istruzione vengono identificate (s’identifica quale strada dovrà prendere l'istruzione dopo la decodifica). Se un'istruzione x86 richiede meno di 4 operazioni Risc per la conversione, viene immediatamente inviata a una delle 4 posizioni di decodifica (Fast path o strada veloce). Le istruzioni x86 complesse che invece richiedono 4 o più operazioni Risc sono trasferite al Microcode Rom (MRom) per la conversione. Una volta che si trovano nella posizione di decodifica le ROPs sono distribuite in parallelo alle stazioni di prenotazione che risiedono in ognuna delle 6 unità di esecuzione della cpu. Una stazione di prenotazione precede l'input a ciascuna unità di esecuzione. Ogni unità ha due stazioni di prenotazione. La cpu invia le ROPs alle stazioni di prenotazione ordinatamente ma quando le ROPs passano nelle unità di esecuzione vengono eseguite fuori sequenza poiché, come già è stato detto in precedenza, le stazioni di prenotazione possono svuotarsi in tempi differenti. Le ROPs aspettano, nelle stazioni di prenotazione, che le unità di esecuzione completino l'elaborazione degli operandi necessari che provengono dall'archivio del registro, dalla cache riservata ai dati o che sono stati inviati da altre unità di esecuzione. Quando un'unità d'esecuzione finisce di elaborare un'istruzione essa ne riceve un'altra dalla stazione di prenotazione. Nell’usare le stazioni in questo modo il processore riduce lo stallo delle istruzioni dovuto alle dipendenze delle risorse di esecuzione (i famosi 8 registri fisici) e permette così un alto tasso di emissione dei dati elaborati.
Buffer di riordino
Il K5 usa un Buffer riordinatore centrale (Central Reorder Buffer) un modo per supportare l'esecuzione speculativa fuori sequenza. Il CRB è usato per rinominare i registri. Il Buffer a 16 ingressi della cpu immagazzina i risultati delle istruzioni x86 eseguite in modo speculativo. Quando le ROPs vengono distribuite alle 6 unità di esecuzione indipendenti, viene allocato un ingresso all'estremità del Buffer Reorder per ogni ROPs eseguita. Vengono allocati contemporaneamente fino a 4 ingressi. Il Buffer tiene traccia della sequenza dell'istruzione originale e si assicura che i risultati vengano ritirati nel giusto ordine, tutto questo lo compie scrivendo i risultati dell’istruzione eseguita nell’archivio del registro.
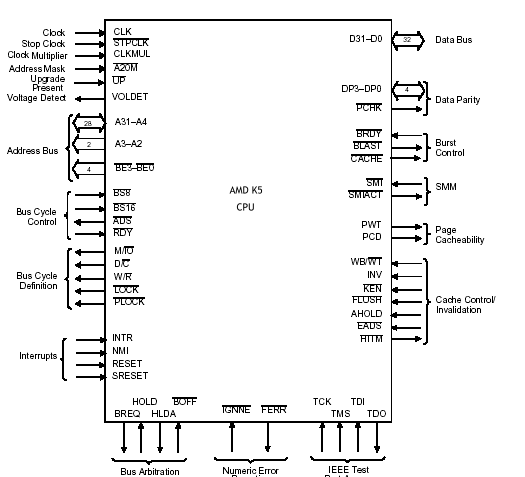
Conclusioni
Il K5 nato come alternativa al Pentium non fu un grande processore o meglio non ebbe il grande successo del suo rivale ma si può anche dire che fu una buona cpu che ha in un certo senso aperto la strada alle future cpu Amd grazie alle sue tecniche di elaborazione abbastanza innovative.